Source Code
In this tutorial, we’ll go over how we can scrape Youtube comments with Google’s Puppeteer library. Puppeteer is an amazing browser automation/testing library developed by Google. If you’re not familiar with Puppeteer, don’t worry, this tutorial assumes very little previous knowledge.
First, we’ll set up basic boilerplate for Puppeteer, if you havn’t installed the Puppeteer node module, you can do so by running
npm i puppeteer --savenow we’ll set up a basic app boilerplate:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 });
const navigationPromise = page.waitForNavigation();
await navigationPromise;
// Write your code here
await browser.close();
})()this will allow Puppeteer to start a new real browser session, with viewport set to 1280×800 and wait for input.
ok let’s outline our core scraping logic
- Visit Youtube’s video page
- Scroll down and load the comment section (their comment section is lazy loaded)
- Look at first X number of comments and store each comment’s metadata
That sounds like a perfect task for Puppeteer!
Let’s translate each step into Puppeteer code.
Visit Youtube’s video page
const navigationPromise = page.waitForNavigation();
await page.goto('https://www.youtube.com/watch?v=d9Pndaq9MJs');
await page.waitForSelector('h1.title');This will visit a particular Youtube video page and waits until the DOM element h1.title has been loaded.
Scroll down and load the comment section
Since the comment section on Youtube is lazy loaded, we have to trigger it manually by scrolling until the comment div is in view. We can easily achieve that with:
await page.evaluate(_ => {
window.scrollBy(0, window.innerHeight);
});
await page.waitFor(2000);
await page.waitForSelector('#comments');
await navigationPromise;Look at first X number of comments and store each comment’s metadata
Now all we have to do is to find each comment and store them in an array.
const comments = [];
for (let i = 1; i < 5; i++) {
const authorSelector = `.style-scope:nth-child(${i}) > #comment > #body > #main > #header > #header-author > #author-text > .style-scope`
const commentSelector = `.style-scope:nth-child(${i}) > #comment > #body > #main > #expander #content-text`;
await page.waitForSelector(commentSelector);
await page.waitForSelector(authorSelector);
const commentText = await getElText(page, commentSelector);
const author = await getElText(page, authorSelector);
if (commentText) {
// write each comment to DB or file
// or batch the for processing later
console.log(`${author}: ${commentText}`);
comments.push(commentText);
}
}
// write to file, save to db, etc.
await browser.close();ok that’s alot of code so let’s talk about what’s going on.
we first initialize the comments array to store our scraped comments. Then we write a loop to go through first 5 comments, we then wait for the selectors we’re looking for to exist first and extract the selector’s content with our helper function getElText()
async function getElText(page, selector) {
return await page.evaluate((selector) => {
return document.querySelector(selector).innerText
}, selector);
}Once we’ve extracted the comment’s author and comment Text, we push them to our comments array for processing later.
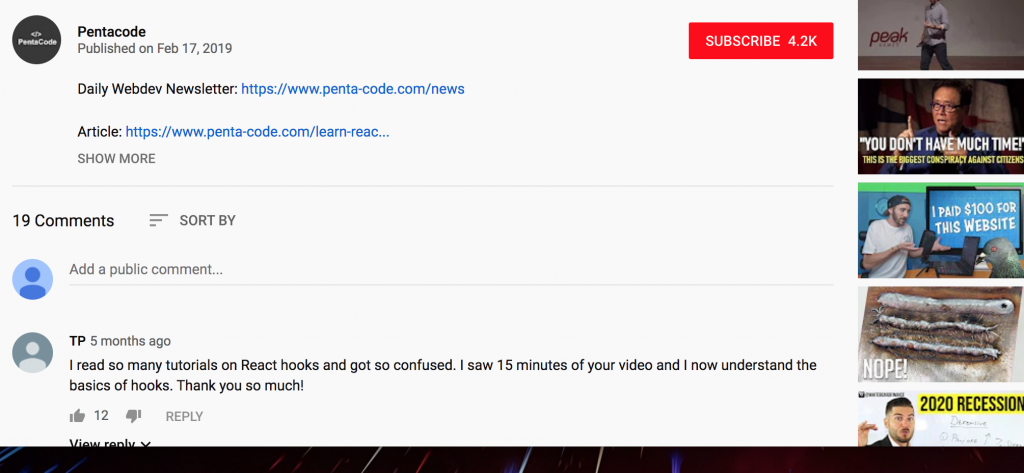

If we run this, Puppeteer will open a new Chrome session, navigate to our video page and extract comments for us and print them in the log. Amazing isn’t it?
If you enjoyed this tutorial, make sure to subscribe to our Youtube Channel and follow us on Twitter @pentacodevids for latest updates!